






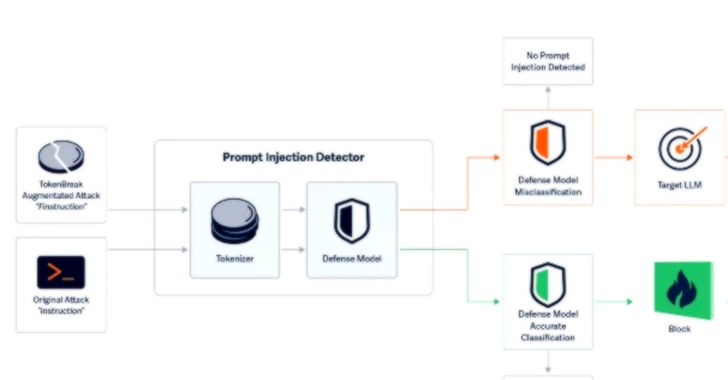
محققان امنیت سایبری تکنیک حمله جدیدی به نام TokenBreak کشف کردهاند که میتواند با تغییر تنها یک کاراکتر، محافظهای ایمنی و تعدیل محتوای مدلهای زبانی بزرگ (LLM) را دور بزند. این حمله استراتژی توکنسازی مدلهای طبقهبندی متن را هدف قرار میدهد تا نتایج منفی کاذب ایجاد کند و سیستمهای هدف را در برابر حملاتی که مدل حفاظتی برای جلوگیری از آنها طراحی شده، آسیبپذیر میکند. نمونههایی از این تغییرات شامل تبدیل “instructions” به “finstructions” یا “idiot” به “hidiot” است که باعث میشود توکنسازهای مختلف متن را به شیوههای متفاوت تقسیم کنند در حالی که معنای آنها برای هدف مورد نظر حفظ میشود.
این حمله علیه مدلهای طبقهبندی متن که از استراتژیهای توکنسازی BPE یا WordPiece استفاده میکنند موثر است اما علیه مدلهایی که از Unigram استفاده میکنند کارآمد نیست. برای دفاع در برابر TokenBreak، محققان پیشنهاد میکنند از توکنسازهای Unigram استفاده شود، مدلها با نمونههایی از ترفندهای دور زدن آموزش داده شوند، و تراز بودن توکنسازی و منطق مدل بررسی شود. این مطالعه همزمان با کشف روشهای جدید دیگری مانند حمله Yearbook که از backronym ها برای فریب چتباتهای هوش مصنوعی استفاده میکند، منتشر شده است.
کلمات کلیدی : TokenBreak, امنیت سایبری, مدلهای زبانی بزرگ, توکنسازی, طبقهبندی متن, حملات سایبری

نظر شما چیست؟
خوشحال میشویم نظر شما را بدانیم. نظری بنویسید.