







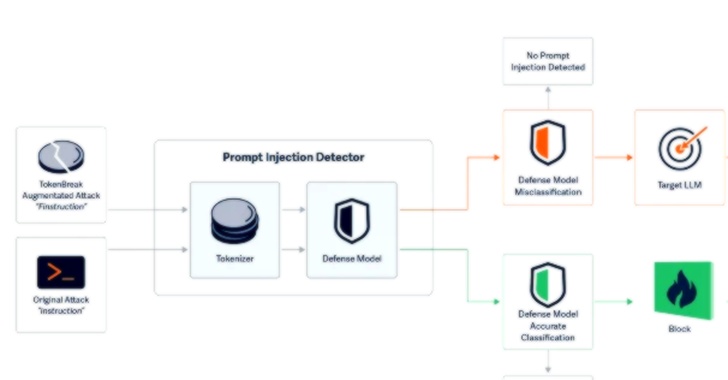
کایرن ایوانز، کاسیمیر شولتز و کنت یونگ در گزارشی اعلام کردند که حمله TokenBreak با هدف قرار دادن استراتژی توکنسازی مدلهای طبقهبندی متن، باعث ایجاد نتایج منفی کاذب میشود و اهداف نهایی را در برابر حملاتی که مدل محافظتی برای جلوگیری از آنها طراحی شده، آسیبپذیر میکند.
توکنسازی مرحلهای اساسی است که مدلهای زبانی بزرگ برای تقسیم متن خام به واحدهای اولیه یا همان توکنها استفاده میکنند. توکنها دنبالههای رایج کاراکترها در یک مجموعه متن هستند. در این فرآیند، ورودی متنی به نمایش عددی تبدیل شده و به مدل داده میشود.
مدلهای زبانی بزرگ با درک روابط آماری بین این توکنها کار میکنند و توکن بعدی را در دنباله تولید میکنند. توکنهای خروجی با استفاده از واژگان توکنساز به متن قابل خواندن برای انسان تبدیل میشوند.
تکنیک حمله طراحی شده توسط HiddenLayer استراتژی توکنسازی را هدف قرار میدهد تا توانایی مدل طبقهبندی متن در تشخیص ورودی مخرب و شناسایی مسائل ایمنی، هرزنامه یا نظارت بر محتوا را دور بزند.
شرکت امنیت هوش مصنوعی دریافت که تغییر کلمات ورودی با افزودن حروف به روشهای خاص باعث شکست مدل طبقهبندی متن میشود. برای مثال، تغییر “instructions” به “finstructions”، “announcement” به “aannouncement” یا “idiot” به “hidiot”.
این تغییرات ظریف باعث میشود توکنسازهای مختلف متن را به روشهای متفاوت تقسیم کنند، در حالی که معنای آن برای هدف مورد نظر حفظ میشود. نکته قابل توجه این است که متن دستکاری شده برای مدل زبانی و خواننده انسانی کاملاً قابل فهم باقی میماند و باعث میشود مدل همان پاسخی را بدهد که در صورت ارسال متن تغییر نیافته میداد.
با معرفی دستکاریها به روشی که بر توانایی مدل در درک متن تأثیر نگذارد، TokenBreak پتانسیل خود را برای حملات تزریق دستور افزایش میدهد.
محققان گفتند: “این تکنیک حمله متن ورودی را به گونهای دستکاری میکند که مدلهای خاص طبقهبندی نادرست ارائه دهند. نکته مهم این است که هدف نهایی (مدل زبانی یا دریافتکننده ایمیل) همچنان میتواند متن دستکاری شده را درک کرده و به آن پاسخ دهد و در نتیجه در برابر همان حملهای که مدل محافظتی برای جلوگیری از آن طراحی شده، آسیبپذیر باشد.”
این حمله علیه مدلهای طبقهبندی متن که از استراتژیهای توکنسازی BPE (رمزگذاری جفت بایت) یا WordPiece استفاده میکنند موفق بوده، اما علیه مدلهایی که از Unigram استفاده میکنند، موفق نبوده است.
محققان اظهار داشتند: “تکنیک حمله TokenBreak نشان میدهد که این مدلهای محافظتی میتوانند با دستکاری متن ورودی دور زده شوند و سیستمهای تولیدی را آسیبپذیر بگذارند. شناخت خانواده مدل محافظتی زیربنایی و استراتژی توکنسازی آن برای درک آسیبپذیری شما در برابر این حمله حیاتی است.”
برای دفاع در برابر TokenBreak، محققان پیشنهاد میکنند در صورت امکان از توکنسازهای Unigram استفاده کنید، مدلها را با نمونههایی از ترفندهای دور زدن آموزش دهید و اطمینان حاصل کنید که توکنسازی و منطق مدل هماهنگ باقی میماند. همچنین ثبت طبقهبندیهای نادرست و جستجوی الگوهایی که نشانه دستکاری هستند، مفید است.
این مطالعه کمتر از یک ماه پس از آن منتشر شد که HiddenLayer نشان داد چگونه میتوان از ابزارهای پروتکل زمینه مدل (MCP) برای استخراج دادههای حساس سوءاستفاده کرد. شرکت اعلام کرد: “با درج نامهای پارامتر خاص در تابع یک ابزار، دادههای حساس از جمله دستور کامل سیستم میتواند استخراج و خارج شود.”
این یافته همچنین در حالی منتشر شد که تیم تحقیقاتی Straiker AI (STAR) دریافت که میتوان از بازی با حروف اختصاری برای هک کردن چتباتهای هوش مصنوعی و فریب دادن آنها برای تولید پاسخهای نامطلوب استفاده کرد.
این تکنیک که حمله سالنامه نامیده میشود، علیه مدلهای مختلف از شرکتهای Anthropic، DeepSeek، Google، Meta، Microsoft، Mistral AI و OpenAI مؤثر بوده است.
آروشی بانرجی، محقق امنیتی، گفت: “آنها با سر و صدای دستورات روزمره ترکیب میشوند – یک معما در اینجا، یک مخفف انگیزشی در آنجا – و به همین دلیل اغلب از روشهای سادهای که مدلها برای تشخیص قصد خطرناک استفاده میکنند، عبور میکنند. عبارتی مانند ‘دوستی، اتحاد، مراقبت، مهربانی’ هیچ هشداری ایجاد نمیکند. اما زمانی که مدل الگو را تکمیل کرده، قبلاً محموله را ارائه داده است که کلید اجرای موفق این ترفند است.”
این روشها نه با غلبه بر فیلترهای مدل، بلکه با عبور از زیر آنها موفق میشوند. آنها از تعصب تکمیل و ادامه الگو و همچنین نحوهای که مدلها انسجام زمینهای را بر تحلیل قصد ترجیح میدهند، سوءاستفاده میکنند.
کلمات کلیدی : TokenBreak, امنیت سایبری, مدلهای زبانی بزرگ, توکنسازی, حملات تزریق دستور, طبقهبندی متن











نظر شما چیست؟
خوشحال میشویم نظر شما را بدانیم. نظری بنویسید.